
#OpenSourceDiscovery 99: Opik
Monitor and evaluate LLM apps

Today I discovered…
Opik
A toolkit to trace LLM calls, add logs to eval dataset with human feedback and LLM auto-judge, run prompt optimization experiments, etc.
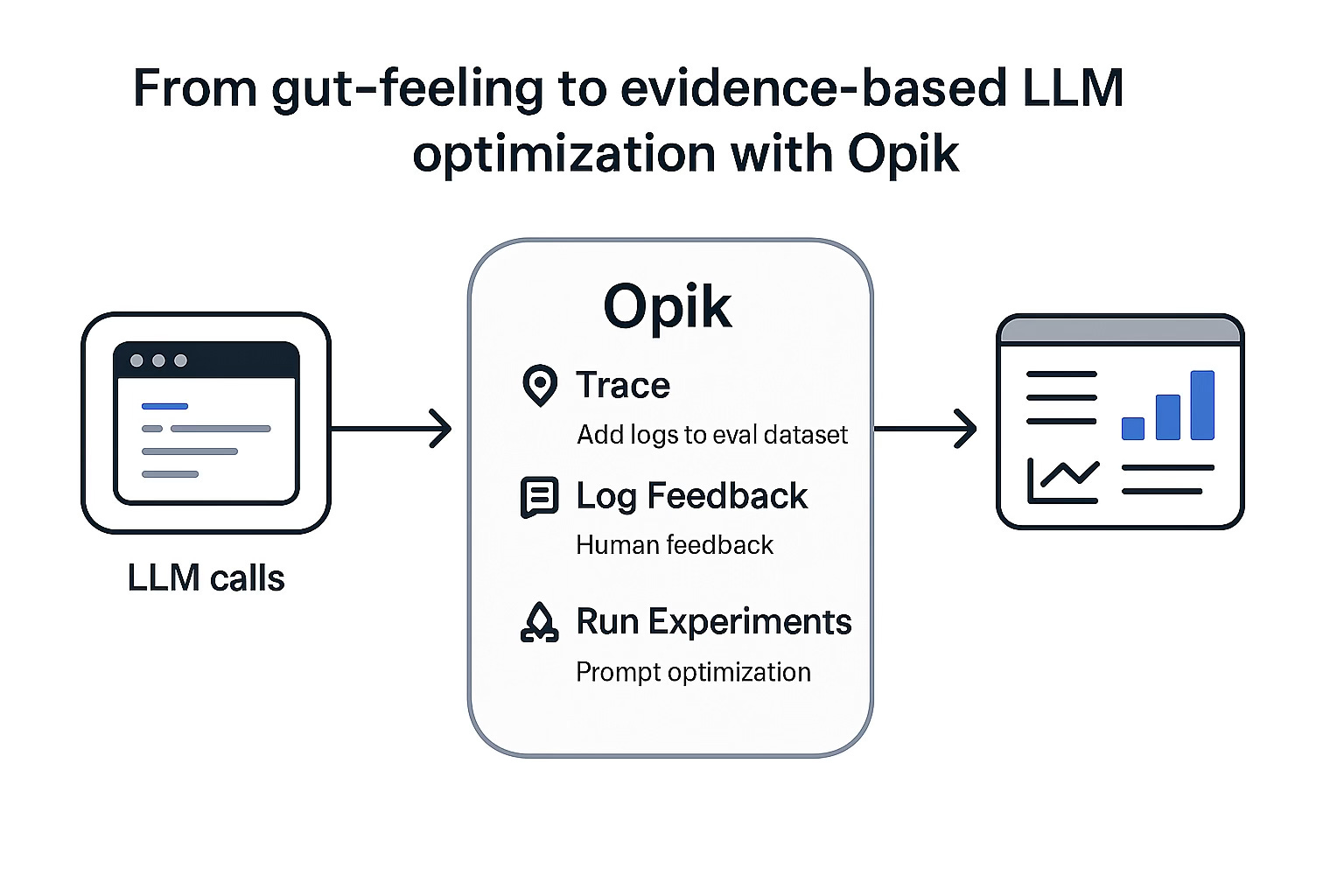
Authors: Thiago dos Santos Hora, Jacques Verré, Andrii Dudar, Andres Cruz, Aliaksandr Kuzmik, BorisTkachenko, and other Comet Team members
Demo | Source
🛡 License: Apache 2.0
Tech Stack: Python, Java, Typescript, React⭐ Ratings and metrics
Based on my experience, I would rate this project as following
Production readiness: 9/10
Docs rating: 8/10
Time to POC(proof of concept): less than an hour
🎯 Why I chose to try Opik:
tl;dr: To fix slow user feedback loop for my AI Agent
It was taking too much time to learn the feedback from my AI Agent users and I almost always ended up with no actionable items because reproducing the same issue was tricky because either they didn’t remember exactly what they did and how LLM responded OR in my case the agent would respond differently. I needed a methodic approach to evaluate how my AI agent was doing and take specific actions based on that to improve it continuously.
I thought of using existing observability tools (e.g. Sentry, New Relic, etc.) but their UX was complex, feature sets did not lead to a meaningful action except for some early stage debugging after tonnes of efforts in setting them up. Of course, the paywall did not encourage exploration either.
I started with OpenAI’s in-built tracing and eval but that is only limited to OpenAI ecosystem, while my agent used multiple LLM providers.
I used BrainTrust and liked its developer experience but it is closed-source and its free plan limitations (2 week data retention only) led me to lose my valuable tracing/feedback.
I thought about building it myself, but it did not seem straightforward to maintain if I were to build it. This is an evolving domain and not the core of the work that I was doing. So although it is critical to my work, it would have been a distraction for me to maintain it.
I needed an Open Source alternative to BrainTrust with similar or better developer experience as BrainTrust and OpenAI’s tracing/eval tools. And this exploration leads me here.
💖 What I like about Opik:
Eval dataset with minimal efforts: It was easy to setup LLM tracing and UI for human feedback, for all LLM providers. I could achieve my end goal of creating and organizing the needed dataset for eval. The overall experience matched my expectations of developer experience set by my earlier use of BrainTrust (closed-source) and OpenAI’s (closed source, limited to OpenAI models) tracing/eval tools while covering their gaps.
Active maintainer participation: One of the Opik’s maintainer responded to my question in a dev community with specific and personalised instructions for my LLM Eval goals. While this category of LLM monitoring and eval is pretty new (but already crowded), this active engagement from maintainers is a good signal that Opik will (hopefully) adapt to developments in LLM ecosystem and user needs faster than others.
Out-of-the box LLM auto-judge evaluations helped remove blank slate dilemma.
👎 What I dislike about Opik:
No support for LLM model fineting. My second priority after the prompt optimisation is to finetune/align the model itself for my specific use case, this need is not yet served by Opik. I would be impressed if it is supported in future making it as easy as fine-tuning OpenAI models via their own tracing/finetuning toolkit (it takes only couple of clicks).
Opik Agent Optimizer and Guardrails seem promising but buggy experience as of now. It is not a critical requirement for me though, I might explore this again once I have developed more trust with manual evaluations.
UX: Although it is not bad but having experienced BrainTrust, I do see some things in UX that can be prioritized e.g. I expect human-feedback and labelling to be quick 1-2 click down only, currently it takes a lot of clicks to get to the human feedback part and then it is not as tidy and quick to do this in bulk.
Overall, I like what Opik has built and I am going to continue using them. I was a bit skeptic at the start given their aggressive advertising campaigns but active participation of maintainers and their past work built the needed trust.
🧑🏻🏫 My actionable advice for Open Source maintainers
Based on my experience with this tool, I would like to highlight some learning for myself as well as other Open Source maintainers out there.
Actively engage with potential users on external dev communities, offer specific and personalised help instead of generic “go try my tool”
Figure out the common need and deliver it as quickly as possible, within as few clicks as possible
Solve the blank canvas problem
Note: In my trials, I always build the project from the source code to make sure that I test what I see on GitHub. Not the docker build, not the hosted version.
If you discovered an interesting Open-Source project and want me to feature it in the newsletter, get in touch with me.
To support this newsletter and Open-Source authors, follow #OpenSourceDiscovery on LinkedIn and Twitter