


#OpenSourceDiscovery 95: ScyllaDB
Real-time NoSQL data store for big data apps

Today I discovered…
ScyllaDB
A distributed NoSQL database leveraging C++ implementation (using Seastar framework) and a shard-per-core architecture to deliver max. hardware utilization with higher throughput and lower latencies
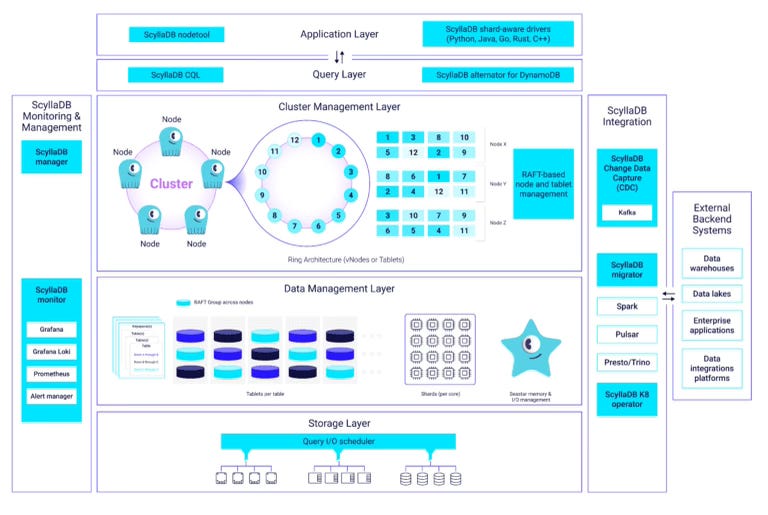
💖 What I like about ScyllaDB:
Shard-per-core architecture. Each CPU core handles a different subset of data. Cores do not share data, but rather communicate explicitly when they need to
It is a vertically scalable system with lesser replicas than Apache Cassandra
Ability to tune consistency vs latency needs based on thoughtful configurations adhering to CAP theorem (demo)
👎 What I dislike about ScyllaDB:
The steep learning curve
I expected more automated performance tuning for the given hardware (as opposed to manual configurations that required learning curve to start with)
Small community size and limited ecosystem (although the swift support and educational material by the staff makes up for this disadvantage to some extent, but a long way to go)
⭐ Ratings and metrics
Based on my experience, I would rate this project as following
Production readiness: 10/10
Docs rating: 8/10
Time to POC(proof of concept): less than two weeks
Author: ScyllaDB team - Avi Kivity @AviKivity, Tomasz Grabiec @tgrabiec, Botond Dénes, Pavel Emelyanov, Benny Halevy, Nadav Har'El, Asias He, Kefu Chai, Raphael Raph Carvalho,Paweł Dziepak @PawelDziepak, Piotr Sarna @sarna_dev, Pekka Enberg @penberg, etc.
Demo | Source
🛡 License: Originally started as AGPL, later added custom terms such as prohibiting database-as-a-service (dBaaS) without a commercial license
Tech Stack: C++If you discovered an interesting Open-Source project and want me to feature it in the newsletter, get in touch with me.
To support this newsletter and Open-Source authors, follow #OpenSourceDiscovery on LinkedIn and Twitter